从表面替换到深度重构:率零DeepHelix引擎的降AI技术路线思考
降AI这个赛道发展了不到两年,技术路线已经分化出两条完全不同的道路。
一条是"表面替换":换几个同义词、调整一下句式、翻译一遍再翻回来。操作简单,成本低,但在2026年知网新算法面前已经基本失效。
另一条是"深度重构":从句式结构和段落节奏层面重新组织文本,改变统计特征本身。技术门槛高,但效果持久。率零(www.0ailv.com)的DeepHelix引擎走的就是这条路。
这篇文章不是教你怎么用工具,而是聊聊降AI这个技术领域的底层逻辑。搞清楚为什么有些方法注定会失效,为什么深度重构是更可持续的方向。
两条技术路线的本质区别
降AI工具面对的核心挑战是:让AI生成的文本在AIGC检测系统面前呈现出人类写作的特征。
实现这个目标有两条截然不同的思路。
路线一:对抗性优化(表面替换)。 核心逻辑是研究检测算法的规则,然后想办法绕过去。比如知网检测"因此"出现频率太高就是AI,那就把"因此"换成"所以"。检测句长太均匀就是AI,那就把一些句子拆长或合短。这种方法像是在和检测系统玩猫捉老鼠的游戏——你绕过了今天的规则,明天规则一更新,又要重新找绕过方式。
路线二:本质改变(深度重构)。 核心逻辑不是去绕过检测规则,而是让文本本身真正变得像人写的。人类写作有什么特点?困惑度高(用词选择不可预测)、突发性强(句子长短参差不齐)、表达多样(不会反复使用同一套模板)。深度重构就是把AI文本的这些统计特征改造到接近人类的水平。不管检测规则怎么变,一篇读起来像人写的文章就是过得了。
这两条路线的差别,就像整容和化妆的区别。化妆(表面替换)能改变表面观感,但卸了妆还是原来的样子。整容(深度重构)改变了底层结构,效果是持久的。
为什么对抗性优化注定不可持续
对抗性优化在早期确实有效。2024-2025年,知网的AIGC检测还停留在词级分析阶段,换几个高频词确实能降不少AI率。但这种方法有一个根本性的问题:你在跟一个不断进化的对手玩追赶游戏,而对手永远有先手优势。
检测系统的升级速度远快于对抗性工具的迭代速度。知网2026年从词级检测升级到了结构级检测,新增了多维特征融合分析和降AI痕迹识别。那些基于词级对抗的工具一夜之间就失效了。
更糟糕的是,对抗性优化本身会留下痕迹。知网的新算法专门针对"被处理过"的文本做识别——如果文本呈现出"前后风格不一致"或"局部过度随机"的特征,反而会被标记。用粗暴的对抗工具处理后,AI率可能不降反升。
DeepHelix的技术选择:从统计特征层面做重构
率零的DeepHelix引擎从一开始就没有走对抗性优化的路线。它的设计目标不是"绕过检测",而是"让文本变自然"。
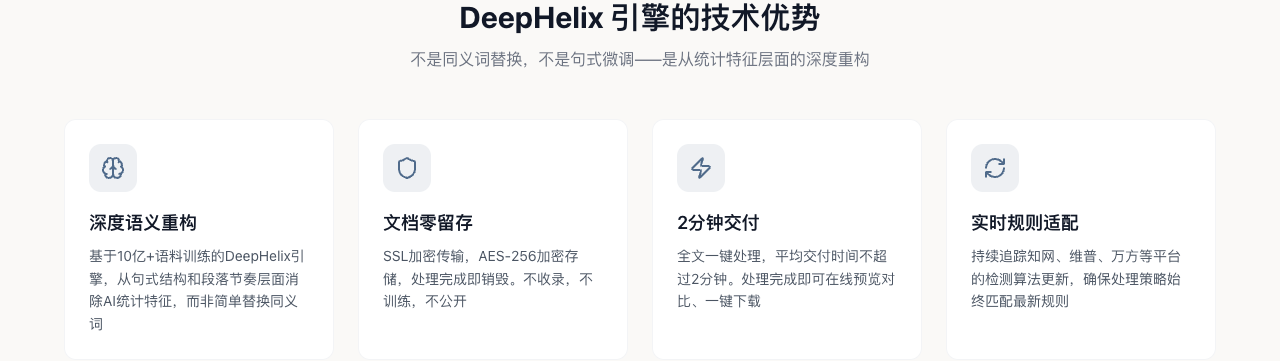
具体来说,DeepHelix做了三层重构:
句式骨架重构。 不是换词,是换结构。同一个意思用完全不同的句式逻辑来表达,打破AI文本"每段都长差不多、每句都结构类似"的模式。处理后的困惑度从AI水平提升到接近人类写作。
段落节奏重构。 AI生成的段落有一种"节拍器"般的规律性——每段差不多长,每句差不多短,过渡词用法差不多。DeepHelix引入自然的节奏变化,有的段落长一些,有的短一些,句子长短参差不齐,像人写的那样有快有慢。
共现特征消除。 基于10亿+语料训练,DeepHelix建立了AI文本的特征图谱,知道哪些词组合、哪些句式模板是AI的"指纹"。处理时会针对性地替换和重组这些特征,让文本不再命中检测系统的特征库。
这三层重构加起来,改变的是文本的统计分布本身,而不是表面的个别词汇。
| 维度 | AI原始文本 | 同义词替换后 | DeepHelix重构后 | 人类写作 |
|---|---|---|---|---|
| 困惑度 | 低(~15) | 低(~16) | 中高(~45) | 高(~50) |
| 句长标准差 | 1.2 | 1.3 | 4.2 | 4.7 |
| 过渡词重复率 | 高 | 中高 | 低 | 低 |
| 知网AI率 | 90%+ | 70-80% | 3-8% | 0-5% |
数据说明一切。同义词替换把困惑度从15提到16,几乎没变。DeepHelix把困惑度提到了45,接近人类的50。这就是"换皮"和"换骨"的差距。
10亿+语料训练意味着什么
DeepHelix引擎的核心竞争力来自它的训练规模:10亿+语料、50万+文档验证。
这个规模意味着什么?
意味着引擎"见过"足够多的人类写作样本。 它知道人类写学术论文时,文献综述段落的句式结构和实验方法段落的句式结构是不同的。它知道社科论文和理工科论文的写作风格有区别。它不是用一套模板处理所有文本,而是根据文本类型和上下文做自适应的重构。
意味着引擎"知道"什么样的统计分布是自然的。 不是随机打乱就行,而是要打乱得"像人一样自然"。人类写作的不规律性也是有规律的——不是完全随机,而是在一定范围内波动。DeepHelix训练了足够多的数据来学习这种"自然的不规律性"。
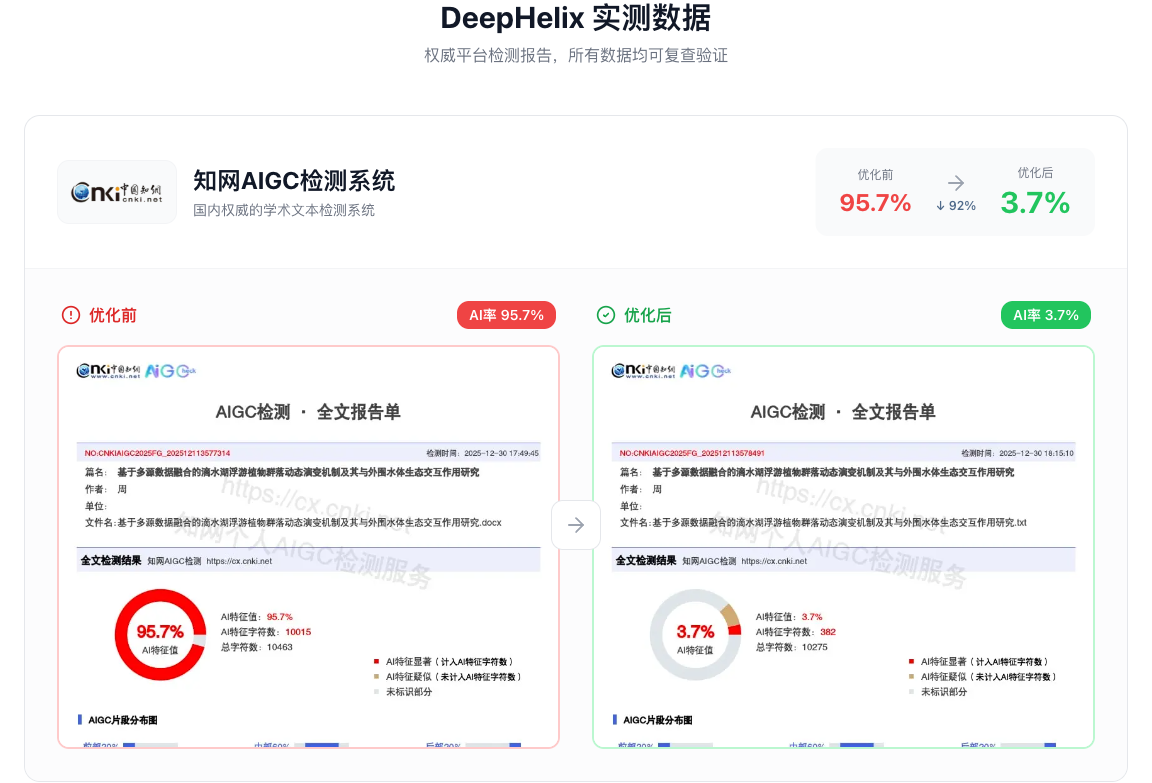
意味着50万+文档的实战验证。 不是实验室里的理论模型,而是在真实论文上反复验证过的效果。知网实测95.7%降至3.7%不是个别案例,而是大样本验证的结果。
行业趋势:从词级到语义级的技术演进
放大视角来看,整个降AI行业正在经历从简单到复杂的技术演进。
第一阶段(2024年):词级处理。 同义词替换、简单改写。技术门槛低,工具多如牛毛,但效果随着检测升级快速衰减。
第二阶段(2025年):句级处理。 句式调整、段落重组。比词级好一些,但仍然是表面层面的改动。
第三阶段(2026年至今):语义级深度重构。 DeepHelix、嘎嘎降AI的双引擎、比话降AI的Pallas引擎,都属于这一代技术。从统计特征层面做重构,效果持久,不怕检测算法升级。
走到第三阶段的工具不多。率零的DeepHelix引擎、嘎嘎降AI(www.aigcleaner.com)的语义同位素+风格迁移双引擎、比话降AI(www.bihuapass.com)的Pallas NeuroClean 2.0、PaperRR(www.paperrr.com)的学术级重构引擎,是目前市面上技术路线最先进的几款。
选择降AI工具时,技术路线比价格更重要。一个走词级替换路线的工具即使免费,在2026年的检测环境下也帮不了你。而一个走语义级重构路线的工具,即使花了钱,至少能确保效果。

常见问题
深度重构会不会过度修改,影响论文质量? DeepHelix的设计原则是"改写法不改意"。保留语义和论证逻辑,只改变表达方式和统计特征。但建议处理后做一次人工复核,确保专业表达准确。
率零的实时规则适配具体是怎么做的? 率零的技术团队会持续监测知网、维普、万方等平台的检测算法变化,根据最新规则调整DeepHelix的处理策略。用户不需要做任何操作,每次使用时引擎都会采用最新版本。
以后检测技术继续升级,深度重构还会有效吗? 只要思路是"让文本变自然"而不是"绕过检测",就不怕升级。检测系统再怎么升级,也无法把一篇真正自然的文本判定为AI——否则就会大量误判人类写的论文,这是检测系统不能接受的。
工具链接汇总:
- 率零:www.0ailv.com
- 嘎嘎降AI:www.aigcleaner.com
- 比话降AI:www.bihuapass.com
- PaperRR:www.paperrr.com